
Bokun Wang
Postdoctoral Researcher at UT Austin
I am a Postdoctoral Fellow in the Department of Electrical and Computer Engineering (ECE) at The University of Texas at Austin, working with Prof. Diana Marculescu and the EnyAC group. Before that, I received my Ph.D. degree in Computer Science at Texas A&M University, advised by Prof. Tianbao Yang.
My research interest lies in Hardware-efficient Generative AI.
Email: bokun.wang@utexas.edu
Research
Hardware-efficient GenAI Inference
Improving hardware efficiency (latency, memory, energy consumption, etc.) of video and language GenAI inference while preserving generation fidelity.
Data/Memory-efficient Contrastive Learning
Memory-efficient and data-efficient (multi-modal) contrastive learning with convergence and generalization guarantees.
Efficient Imbalanced and Multi-instance Medical Image Analysis
Memory-efficient provable algorithms for high-res, imbalanced multi-instance medical image analysis.
Recent Work (Full List)
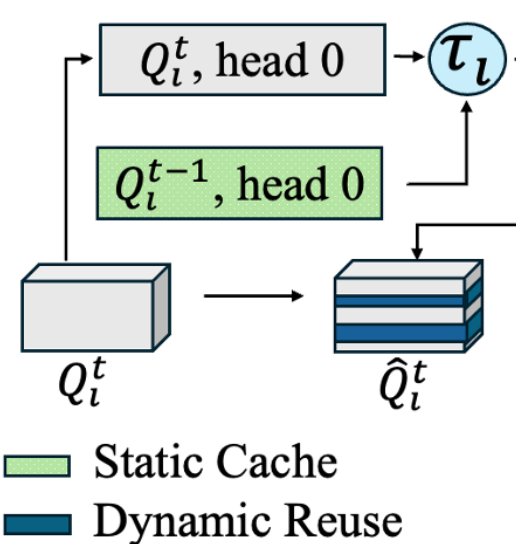
DARE: Diffusion Language Model Activation Reuse for Efficient Inference
Natalia Frumkin, Bokun Wang, Hung-Yueh Chiang, Chi-Chih Chang, Mohamed S. Abdelfattah, and Diana Marculescu
ArXiv Preprint, 2026

Awards and Recognitions
- Early Career Postdoctoral Fellowship, The University of Texas at Austin, 2026.
- Selected Participant of FutureBAProf, Tippie College of Business, The University of Iowa, 2026.
- Gold Reviewer Award, International Conference on Machine Learning (ICML), 2026.
- Oral Presentation, Conference on the Mathematical Theory of Deep Neural Networks (DeepMath), 2024.
- Spotlight Presentation, International Conference on Learning Representations (ICLR), 2022.
- Provincial Outstanding Graduate, Sichuan Province, China, 2018.
- Lixin Tang Scholarship, University of Electronic Science and Technology of China, 2017.
- National Scholarship, Ministry of Education of the People’s Republic of China, 2016.
- Freshman Scholarship, University of Electronic Science and Technology of China, 2014.
Teaching
- Guest Instructor, CSCE 689: Optimization for Machine Learning (Fall 2023), Texas A&M University.
- Teaching Assistant, ECS 32B: Introduction to Data Structures (Winter 2020), University of California Davis.
- Teaching Assistant, ECS 154A: Computer Architecture (Fall 2019), University of California Davis.
- Teaching Assistant, ECS 170: Introduction to Artificial Intelligence (Spring 2019), University of California Davis.
- Teaching Assistant, ECS 271: Machine Learning and Data Discovery (Winter 2019), University of California Davis.